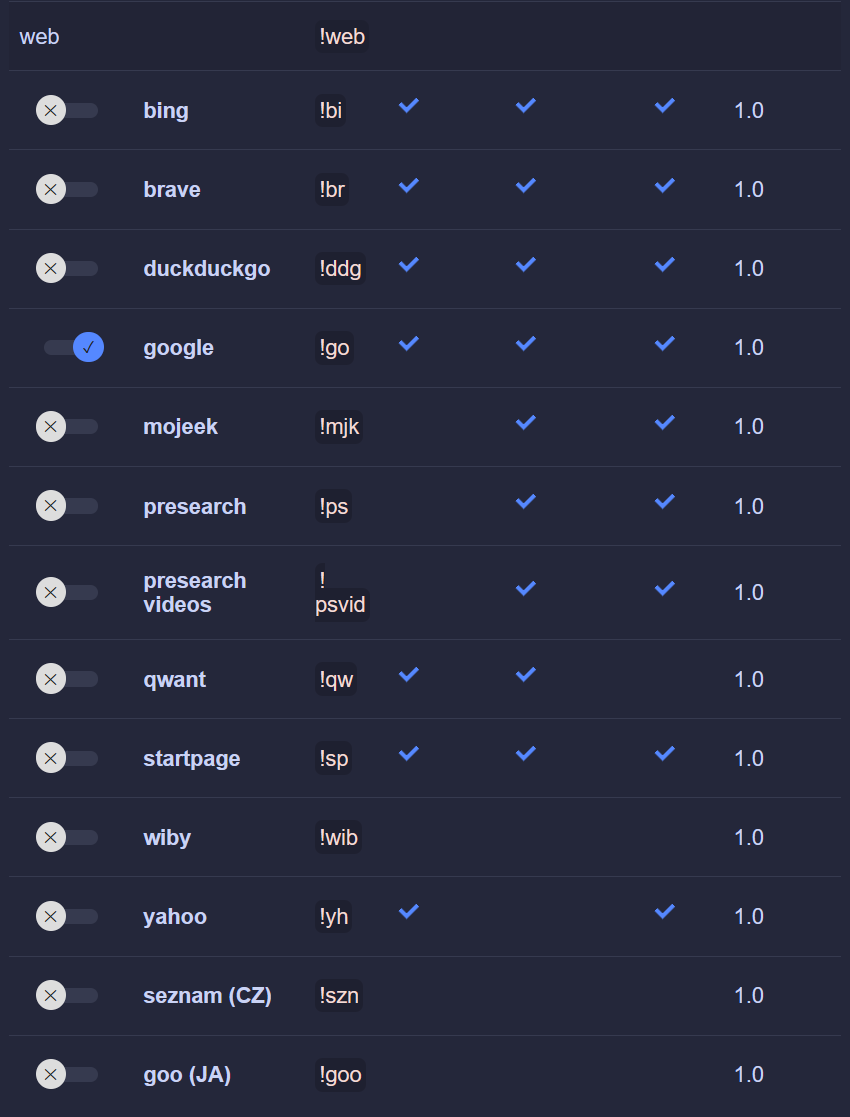
I noticed that when you have the assistant summarize a site for example, there will be around 10 requests made by at least 2 different search engine crawlers. Google being the most aggressive one.
I don't think this is a good thing, if people use Kagi's assistant in for example professional setting, this will eventually lead into leaking secrets to these search engines. I kinda assumed that Kagi had some privacy with the API's it uses from these providers, like with the LLM API's.
Toggling the web access off from assistant is a "fix" to this, but this seems like it's an issue that might need some consideration.